2021. 2. 9. 08:06ㆍ알고리즘/알고리즘 정리
1. 트라이
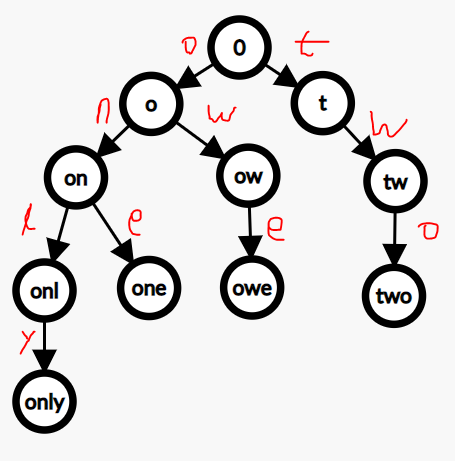
문자열은 두 변수를 비교하는데 최악의 경우 문자열의 길이에 비례하는 시간이 걸린다.
그러므로 이진 검색 트리에서 문자열을 찾는데에 O(mlgn) 의 시간이 걸릴 수 있다.
이와 같은 문제점을 해결하기 위해 고안된 문자열의 특화 자료 구조가 바로 트라이(trie) 이다.
트라이는 문자열의 집합을 표현하는 트리 자료 구조로 검색 수행시 O(M)의 시간이 걸린다.
- 트라이는 집합에 포함된 문자열의 접두사들에 대응되는 노드들이 서로 연결된 트리이다.
- 한 접두사의 맨 뒤에 글자를 덧붙여 다른 접두사를 얻을 수 있을 때 두 노드는 부모 자식 관계로 연결된다.
- 트라이의 루트는 항상 길이 0 인 문자열에 대응된다.
- 깊이가 깊어질 수록 대응되는 문자열의 길이는 1 씩 증가한다.
트라이에서 중요한 속성은 루트에서 한 노드까지 내려가는 경로에서 만나는 글자들을 모으면 해당 노드에 대응되는
접두사를 얻을 수 있다는 것, 그로인해 문자만을 저장할 수 있다는 것이다.
2. 트라이 구현
자손 노드들을 가리키는 포인터 목록,
이 노드가 종료 노드인지를 나타내는 불린 값 변수로 구성된다.
자손 노드들을 가리키는 포인터들은 입력에 등장 할 수 있는 모든 문자에 대응되는 원소를 갖는
고정 길이 배열로 구현된다. ( 알파벳 26개 = 26개의 포인터 배열, 해당 문자가 없으면 NULL)
다음은 책에 나와있는 find와 insert 코드이다.
두 개의 연산은 문자열의 길이만큼 수행하기 때문에, 두 함수의 시간 복잡도는 모두
문자열의 길이 M에 비례한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
const int ALPHABETS = 26;
int toNumber(char ch) {return ch - 'A';}
struct TrieNode {
TrieNode* children[ALPHABETS];
bool terminal;
TrieNode() : terminal(false) {
memset(children, 0, sizeof children);
}
~TrieNode() {
for(int i = 0; i < ALPHABETS; i++)
if(children[i])
delete children[i];
}
void insert(const char* key) {
if(*key == 0)
terminal = true;
else {
int next = toNumber(*key);
if(children[next] == NULL)
children[next] = new TrieNode();
children[next]->insert(key+1);
}
}
TrieNode* find(const char* key) {
if(*key == 0) return this;
int next = toNumber(*key);
if(children[next] == NULL) return NULL;
return children[next]->find(key+1);
}
};
|
cs |
3. 트라이의 문제점
트라이의 가장 큰 문제점은 메모리가 많이 필요하다는 것이다
26개의 알파벳에서 각각 26개의 알파벳이 생기는 것이니 메모리가 많이 필요하다.
이를 해결하기 위해 만들어진 트리플 어레이 트라이(triple-array trie)는 거대한 일차원 배열을 할당 받은 뒤 노드들이 이들을 공유하도록한다.(대다수 노드들의 자식 노드 포인터 배열이 대부분 비어있다는점을 이용)
기수 트리, 패트리샤 트리 또한 메모리 절약을 위해 트라이를 압축한 자료 구조이다.
4. 접미사 트라이(suffix trie) => 접미사 트리(suffix tree)
한 문자열 S의 모든 접미사를 트라이에 집어 넣은 것.
문자열의 모든 부분 문자열은 결국 어떤 접미사의 접두사이다.
트라이는 저장된 문자열의 모든 접두사들을 저장하기 때문에
접미사 트라이는 문자열의 모든 부분 문자열에 대응되는 노드를 가지고 있게 된다.
트라이를 이용하게 되면 역시 메모리가 문제가 된다.
이를 위해 고안된 것이 접미사 트리이다.
접미사 트라이의 많은 부분이 분기 없이 일자로 구성되어 있다는 것을 이용한 것이다.
이런 부분을 노드 하나로 표현하여 메모리를 절약한다.
접미사 트리의 각 간선은 원 문자열의 일부에 대응되며, 해당 부분 문자열의 첫 글자와 마지막 글자의 위치로 표현한다.
이렇게 표현된 접미사 트리의 노드의 총 개수는 최대 O(N)이 된다고 한다.
접미사 트리를 만드는 단순한 알고리즘은 O(n^2)이기 때문에 알고리즘 문제에선 잘 사용하지 않는다고 한다.
접미사 배열을 쓰도록하자.
5. 아호-코라식 문자열 검색 알고리즘
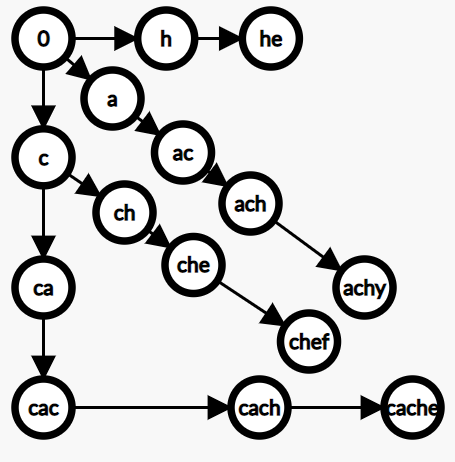
트라이는 한 집합에서 문자열을 찾는 용도 외에
한 문자열에서 여러개의 문자열을 찾는 용도로 쓸 수 있다.
한 문자열에서 한 문자열을 찾는 kmp 알고리즘은 여러개의 문자열을 찾고자 할 때
한개 검사후 다시 처음부터 조사해야하므로 번거롭다.
하지만 트라이를 사용하여 찾고자하는 문자열을 하나의 트라이로 표현하여
실패함수를 작성하면 한번에 찾을 수 있다.
이는 접두사를 공유할 경우 이 접두사들은 같은 노드에 대응한다는 점을 이용한 것이며
이를 이용해 탐색 공간을 줄인 것이다.
위 그림은 cache chef achy he 를 하나의 트라이로 표현한 것이다.
6. 아호-코라식 문자열 검색 알고리즘: 실패 함수
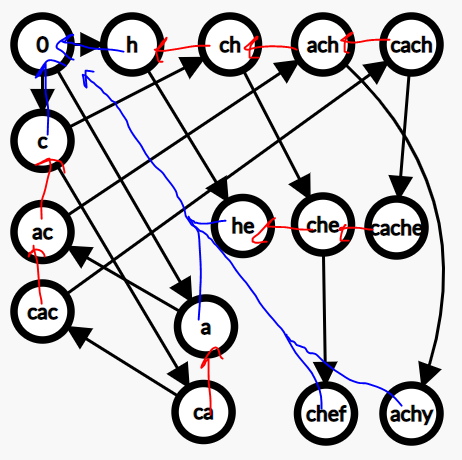
위 그림은 실패함수가 적용된 트라이의 모습을 대충 그려본 것이다.
실패 함수의 정의는 다음과 같다.
failure(s) = s의 접미사이면서 s의 접미사보다 짧고 트라이에 포함된 가장 긴 문자열까지 가는 화살표
(s는 s의 접미사이므로.(진접미사 proper suffix))
실패 함수를 만들기 위해서는 다음과 같은 정보가 필요하다
- 실패연결(failure link): 이 노드에서의 실패 함수 값. 이 노드에서 다음 글자가 대응하는 데 실패했을 때 다음으로 가서 시도해야 할 노드의 포인터
- 출력 문자열 목록: 각 노드에 도달했을 때 어떤 바늘 문자열들을 발견하게 되는지를 저장한다.
문자열이 종료되는 노드 외에도 문자열을 발견할 수 있기 때문에 필요하다.
|
1
2
3
4
5
|
struct TrieNode {
int terminal;
TrieNode* fail;
vector<int> output;
};
|
cs |
주어진 노드에서 실패 연결을 계산하는 가장 간단한 방법은 모든 접미사를 하나하나 시도하는 것이다.
이 보다 빠르게 계산하는 핵심 아이디어는
부모노드의 실패연결을 이용해 자식 노드의 실패 연결을 쉽게 알 수 있다는 점을 이용하는 것이다.
부모노드 + x = 자식노드
접미사에 x를 붙인게 자식노드이다
따라서 부모노드의 실패함수에 x를 붙인것이 있으면 자식 노드의 실패 함수가 된다.
또한 만약 x 가 붙인것이 없으면 실패연결을 따라 올라가면된다.
실패함수를 따라가면 접미사에 a 가 붙은 꼴의 노드를 자식으로 가지는 노드가 나오게 된다.
a == x 이면 이것을 연결해주면된다.
만약 루트로 올라갈때 까지 찾지못하면 실패연결 값은 루트가 된다.
실패연결을 따라갈때 만나는 문자열들은 원래 노드의 문자열 길이보다 항상 짧기 때문에,
루트에서부터 시작해서 깊이가 낮은 노드들 부터 순서대로 실패 연결을 하면,
위와 같은 방법을 사용할 수 있다.
(깊이 우선 탐색을 하게되면 실패연결을 따라 올라 갈 때 실패연결값을 구하지 못한 노드가 있을 수 있음)
출력 문자열 목록을 계산할때
실패연결을 계산하고 나면 해당 위치에서 출력 문자열 목록을 복사해온 뒤, 현재 위치에서 끝나는 문자열을 추가한다.
=
현재 노드에 대응되는 문자열의 접미사가 트라이에 포함된 어떤 문자열과 같다면, 이 노드에서 실패 연결을 따라가다 보면 이 문자열을 반드시 찾을 수 있기 때문이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
struct TrieNode {
int terminal;
TrieNode* fail;
vector<int> output;
};
void computeFailFunc(TrieNode* root) {
queue<TrieNode*> q;
root->fail = root;
q.push(root);
while(!q.empty()) {
TrieNode* here = q.front();
q.pop();
for(int edge = 0; edge < ALPHABETS; ++node) {
TrieNode* child = here->children[edge];
if(!child) continue;
if(here == root)
child->fail = root;
else {
TrieNode* t = here->fail;
while(t!=root&&t->children[edge] == NULL)
t = t->fail;
if(t->children[edge]) t = t->children[edge];
child->fail = t;
}
child->output = child->fail->output;
if(child->terminal != -1)
child->output.push_back(child->terminal);
q.push(child);
}
}
}
|
cs |
7. 아호-코라식 알고리즘 탐색 과정
kmp알고리즘과 출력문자열 목록을 제외하면 비슷하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
vecotr<pair<int, int> > ahoCorasick(const string& s, TrieNode* root) {
vector<pair<int, int> > ret;
TrieNode* state = root;
for(int i = 0; i < s.size(); ++i) {
int chr = toNumber(s[i]);
while(state != root && state->children[chr] == NULL)
state = state->fail;
if(state->children[chr]) state = state->children[chr];
for(int j = 0; j < state->output.size(); j++)
ret.push_back(make_pair(i, state->output[j]));
}
}
return ret;
}
|
cs |
8. 아호-코라식 알고리즘 시간 복잡도 계산
탐색 함수에서의 시간복잡도는
for문안에 있는 반복문들에 의해 지배된다.
출력 문자열 목록을 순회하는 for문은 찾고자하는 문자열들의 출현 횟수 P 만큼 수행된다.
while문은 총 수행 시간은 실패연결을 몇번이나 따라 내려가는지를 알아야한다.
현재 state가 실패할경우 실패함수를 따라가며 문자열의 길이가 1씩줄어든다.
이는 s의 현재 해당하는 인덱스 i 부터 0까지의 길이보다 짧으며,
끝까지 따라 내려가더라도 이때 까지 일치했던것까지만 내려가 다시 길이 0 부터 다시 조사한다.
현재 s의 길이 를 초과해서 따라 내려갈 수 없으므로 s의 길이 N에 비례한다고 할 수 있다.
두 반복문의 총 수행 횟수는 O(N + P) 이다.
실패함수의 시간 복잡도는
실패 연결을 따라 내려가는 while문에 지배된다.
이 while문은 트라이의 찾고자하는 문자열의 길이에 비례한다.
최악의 경우는 보통 리프 문자열들에서 생긴다.
1. while 과 for 문 총 수행 횟수 bfs 탐색 => 찾고자하는 문자열들의 합 M
2. 실패연결 while문
=> 최악의 경우 리프 문자열들 루트까지 내려갈때 M
(리프에서 최악의 경우 모든 실패연결을 탐색할 경우 문자열 길이에 비례하며 이는 리프당 하나 발생할 수 있다.
그러므로 전체 문자열들의 합 M이 걸릴 수 있다.)
=> 모든 노드에서 각 노드를 처리하는데 보통 상수시간이 걸린다 M
따라서 총 수행횟수는 3M이므로 O(M)의 시간 복잡도를 가진다.
(출력문자열 목록의 복사는 연결 리스트를 써서 해결)
아호-코라식 알고리즘의 시간복잡도는
전처리를 포함한 아호-코라식 알고리즘의 시간 복잡도는
따라서 O(N + M + P) 이다.
메모리 절약을 위한 아호-코라식 구현
메모리를 절약하기 위한 아호-코라식 알고리즘
문자열의 속성에 따라 ("A" "AA" "AAA"..)
각 노드의 출력 문자열 목록들은 O(M^2)의 공간을 차지하게 될 수 있다
트라이의 각 노드의 출력 문자열 목록은 실패 연결을 따라간 노드의 출력 문자열 목록의 원소를
포함한다는 점을 이용하면 이 문제를 해결할 수 있다.
출력 문자열 목록의 원소들을 연결 리스트에 넣어 보관하게 되면
복사해오는 대신 해당 목록의 머리를 가리키도록하면 메모리를 아낄 수 있다.
-알고리즘 문제해결전략 781p
'알고리즘 > 알고리즘 정리' 카테고리의 다른 글
| [그래프] Graph 2: DFS 그래프의 깊이 우선 탐색, 위상 정렬 (0) | 2021.02.11 |
|---|---|
| [그래프] Graph 1: 그래프의 표현과 정의 (0) | 2021.02.11 |
| [트리] Tree 8: Disjoint Set 상호 배타적 집합, 유니온-파인드 (0) | 2021.02.08 |
| [트리] Tree 6: Segment Tree구간 트리 , RMQ, 펜윅 트리(이진 인덱스 트리) (0) | 2021.02.07 |
| [트리] Tree 5: 우선순위 큐와 이진 힙 (0) | 2021.02.06 |